Introduction
This is a demo website for paper “MUSIC SOURCE SEPARATION USING GENERATIVE ADVERSARIAL NETWORKS”
Abstract
Music source separation is an important task for many applications in music information retrieval field. However, due to the complexity of the music signal t is still considered a challenging task. In this paper, we propose a novel approach extending Wasserstein generative adversarial networks to source separation task. We used the mixture signal as a condition to generate sources and applied the U-net style network for the stable training of the model. Experiments with the DSD100 dataset show the promising results with the potential of using the GANs for music source separation.
Spectrograms
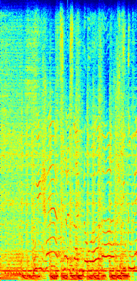
(a)Mixture
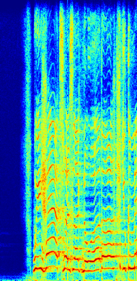
(b)True Vocal
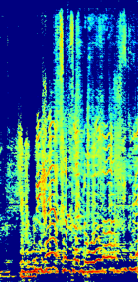
(c)Estimated vocal using only generative adversarial loss
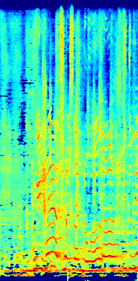
(d)Estimated vocal using only L1 loss
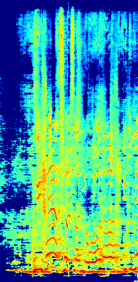
(e)Estimated vocal using both generative adversarial loss and L1 loss
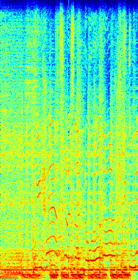
(a)Mixture
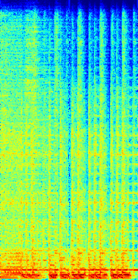
(b)True Accompaniment
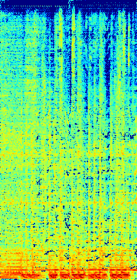
(c)Estimated accompaniment using only generative adversarial loss
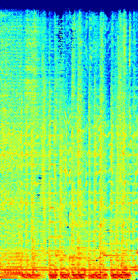
(d)Estimated accompaniment using only L1 loss
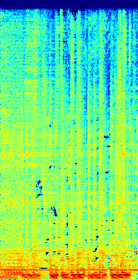
(e)Estimated accompaniment using both generative adversarial loss and L1 loss
Audio Samples
Due to the copyright problem, the original songs for our samples are linked down below.
Only GANs loss
| Vocal | Accompaniment | Original Song | |
|---|---|---|---|
| Cold Play - Paradise | Youtube Link | ||
| Gallant - Episode | Youtube Link | ||
| Michael Jackson - Beat it | Youtube Link | ||
| Red Velvet – Red Flavor | Youtube Link |
Only L1 loss
| Vocal | Accompaniment | Original Song | |
|---|---|---|---|
| Cold Play - Paradise | Youtube Link | ||
| Gallant - Episode | Youtube Link | ||
| Michael Jackson - Beat it | Youtube Link | ||
| Red Velvet – Red Flavor | Youtube Link |
GANs + L1 loss
| Vocal | Accompaniment | Original Song | |
|---|---|---|---|
| Cold Play - Paradise | Youtube Link | ||
| Gallant - Episode | Youtube Link | ||
| Michael Jackson - Beat it | Youtube Link | ||
| Red Velvet – Red Flavor | Youtube Link |